

Introduction
At TrendLab, we talked about the added value of contextual information. This topic generated a lot of interest and follow-up discussion, which is why I’m taking the opportunity here to share some additional information to help you on the way. We’ll focus on ODBC here, but the steps and queries for JDBC will be very similar.
When setting up a Generic ODBC data source in TrendMiner for the Event capability, you'll need to configure multiple queries to properly integrate your event data. In this post, we’ll demonstrate all required query structures for connecting to databases like SQL Server, Oracle, or other ODBC-compatible sources.
Note that the queries may need small adjustments to work with your specific data source. E.g. to only select 10 rows in MySQL, you’d use “LIMIT 10”, whereas Oracle uses a different syntax, e.g. “Rownum<=10”. Sometimes the syntax may even slightly vary between database versions. Therefore we always recommend checking the documentation of your specific database driver. In the example below, the queries follow the SQL Server syntax.
Prerequisites
Before implementing these queries, ensure you have:
- A configured Generic ODBC data source in ConfigHub with Event capability enabled
- Proper ODBC drivers installed on your Plant Integrations server
- A valid connection string with appropriate credentials
- Understanding of your source database schema and table structures
For detailed setup instructions, refer to the official documentation.
Queries
In the queries below, we will be working with the following table structures
- TM_CONTEXT_ITEMS

- TM_CONTEXT_FIELDS

Events query
This query retrieves events from your source database within a specified time range. TrendMiner uses a streaming event approach, so that open context events (e.g. an ongoing OEE loss or batch record) can be created as soon as it begins, and each subsequent state can be ingested right away. If you have a flat table where each row corresponds to exactly 1 context item, and the states are distributed in the columns instead, some data processing may be required.
In the example below, we have such a case with 2 possible states: Started and Ended.
WITH StartedEvents AS
( SELECT
CONCAT(ID,'_0') as id,
ID as name,
'TM_CONTEXT_ITEM' as type,
START_TIME as occurred_at,
MODIFIED_TIME as modified_at,
'/' as components,
'Started' as state,
null as description,
null as keywords,
ID as grouping_key
FROM TM_CONTEXT_ITEMS
WHERE
START_TIME > {AFTER}
AND START_TIME < {BEFORE}
),
EndedEvents AS
( SELECT
CONCAT(ID,'_1') as id,
ID as name,
'TM_CONTEXT_ITEM' as type,
END_TIME as occurred_at,
MODIFIED_TIME as modified_at,
'/' as components,
'Ended' as state,
null as description,
null as keywords,
ID as grouping_key
FROM TM_CONTEXT_ITEMS
WHERE
END_TIME > {AFTER}
AND END_TIME < {BEFORE}
),
Events AS
( SELECT * FROM StartedEvents
UNION SELECT * FROM EndedEvents
)
SELECT TOP ({LIMIT}) * FROM Events
WHERE
id > coalesce({CURSOR}, '0')
ORDER BY id ASCThe logic behind this query is:
- Dual Event Creation: Each record in the source table generates two events:
- A "Started" event at the
START_TIMEwith ID suffix_0 - An "Ended" event at the
END_TIMEwith ID suffix_1
- A "Started" event at the
- Grouping Key: Both events share the same
grouping_key(the original ID), allowing TrendMiner to associate related start/end events - Event Identification: The modified IDs (
_0and_1suffixes) ensure unique identification while maintaining the relationship through the grouping key - All events are then combined in the final query, and the first
{LIMIT}events are selected. The next paginated query will continue from this location through the{CURSOR}variable - In this simple example, the context items are linked to the root asset node, identified as
/
Event by ID query
This query retrieves a specific event by its unique identifier.
WITH StartedEvents AS
( SELECT
CONCAT(ID,'_0') as id,
ID as name,
'TM_CONTEXT_ITEM' as type,
START_TIME as occurred_at,
MODIFIED_TIME as modified_at,
'/' as components,
'Started' as state,
null as description,
null as keywords,
ID as grouping_key
FROM TM_CONTEXT_ITEMS
WHERE
ID = SUBSTRING({ID}, 1, LEN({ID})-2)
),
EndedEvents AS
( SELECT
CONCAT(ID,'_1') as id,
ID as name,
'TM_CONTEXT_ITEM' as type,
END_TIME as occurred_at,
MODIFIED_TIME as modified_at,
'/' as components,
'Ended' as state,
null as description,
null as keywords,
ID as grouping_key
FROM TM_CONTEXT_ITEMS
WHERE
ID = SUBSTRING({ID}, 1, LEN({ID})-2)
),
Events AS
( SELECT * FROM StartedEvents
UNION
SELECT * FROM EndedEvents
)
SELECT * FROM Events
WHERE
id = {ID}The logic is the same as before - we create dual events for the Started and Stopped events, and then select the unique result with the final WHERE clause.
Types Query
In this example, we will create a single, hardcoded type “TM_CONTEXT_ITEM” for all events. We also used this same identifier in the events queries above. Note that this type should be unique across all your connections, so it’s strongly recommended to use a longer, descriptive and unique id. The type has 3 fields, which we provide unique technical identifiers: TM_CONTEXT_FIELD1, TM_CONTEXT_FIELD2 and TM_CONTEXT_FIELD3. These refer to the technical identifier of the fields in the Fields query, defined below.
WITH EventTypes AS (
SELECT
'TM_CONTEXT_ITEM' as id,
'TrendMiner External Context' as name,
'DB1F1F' as color,
'Started' as startstate,
'Ended' as endstate,
'Started,Ended' as states,
'TM_CONTEXT_FIELD1,TM_CONTEXT_FIELD2,TM_CONTEXT_FIELD3' as fields
)
SELECT * from EventTypes
WHERE
id > coalesce({CURSOR}, '0')Type by ID Query
The type by ID query is used to refresh individual context item types. In this simple example, the resulting query will look almost identical, since it was hardcoded.
WITH EventTypes AS (
SELECT
'TM_CONTEXT_ITEM' as id,
'TrendMiner External Context' as name,
'DB1F1F' as color,
'Started' as startstate,
'Ended' as endstate,
'Started,Ended' as states,
'TM_CONTEXT_FIELD1,TM_CONTEXT_FIELD2,TM_CONTEXT_FIELD3' as fields
)
SELECT * from EventTypes
WHERE
id = {ID}Fields Query
This query returns a list of possible custom fields from the source database. As mentioned above, we’re going to assume that a small table, “TM_CONTEXT_FIELDS”, exists in the database that has a row containing all relevant details for each field. This truly simplifies this and the next query, and is therefore a recommended approach. Once again, note that the identifier for each field should be unique across all your connections, so it’s strongly recommended to use a longer, descriptive and unique id.
SELECT id, name, type, placeholder, options
FROM TM_CONTEXT_FIELDS
WHERE id > coalesce({CURSOR}, '0')Fields by ID Query
This query looks almost identical to the previous, except for the WHERE clause that filters for the ID.
SELECT id, name, type, placeholder, options
FROM TM_CONTEXT_FIELDS
WHERE id = {ID}Event Fields Query
This query returns the values for the custom fields attached to a given specific Event. The event is identified by the ID, but we need to remove the “_0” and “_1” postfixes that were added to identify Start and End event.
We are re-using the technical identifiers from the Types query, and assign the values that are in the original table’s columns named FIELD1, FIELD2 and FIELD3.
WITH event as (
SELECT * FROM TM_CONTEXT_ITEMS
WHERE ID = SUBSTRING({ID}, 1, LEN({ID})-2)
),
fieldvalues as (
SELECT 'TM_CONTEXT_FIELD1' AS fieldId, FIELD1 AS value FROM event
UNION ALL
SELECT 'TM_CONTEXT_FIELD2' AS fieldId, FIELD2 AS value FROM event
UNION ALL
SELECT 'TM_CONTEXT_FIELD3' AS fieldId, FIELD3 AS value FROM event
)
SELECT * FROM fieldvalues WHERE value IS NOT NULLEvents by Grouping Key Query
This query retrieves all events that belong to the same group. It will look very similar to the Events by ID query, only this time it will filter for all events with the same Grouping Key.
WITH StartedEvents AS
( SELECT
CONCAT(ID,'_0') as id,
ID as name,
'TM_CONTEXT_ITEM' as type,
START_TIME as occurred_at,
MODIFIED_TIME as modified_at,
'/' as components,
'Started' as state,
null as description,
null as keywords,
ID as grouping_key
FROM TM_CONTEXT_ITEMS
WHERE
ID = {GROUPINGKEY}
),
EndedEvents AS
( SELECT
CONCAT(ID,'_1') as id,
ID as name,
'TM_CONTEXT_ITEM' as type,
END_TIME as occurred_at,
MODIFIED_TIME as modified_at,
'/' as components,
'Ended' as state,
null as description,
null as keywords,
ID as grouping_key
FROM TM_CONTEXT_ITEMS
WHERE
ID = {GROUPINGKEY}
),
Events AS
( SELECT * FROM StartedEvents
UNION
SELECT * FROM EndedEvents
)
SELECT * FROM Events
Results
Once the queries have been generated, a synchronization (historical or live) can be enabled in ConfigHub. The result set, as shown in ContextHub, will look like this (shown in the new Dark Mode for TrendMiner).
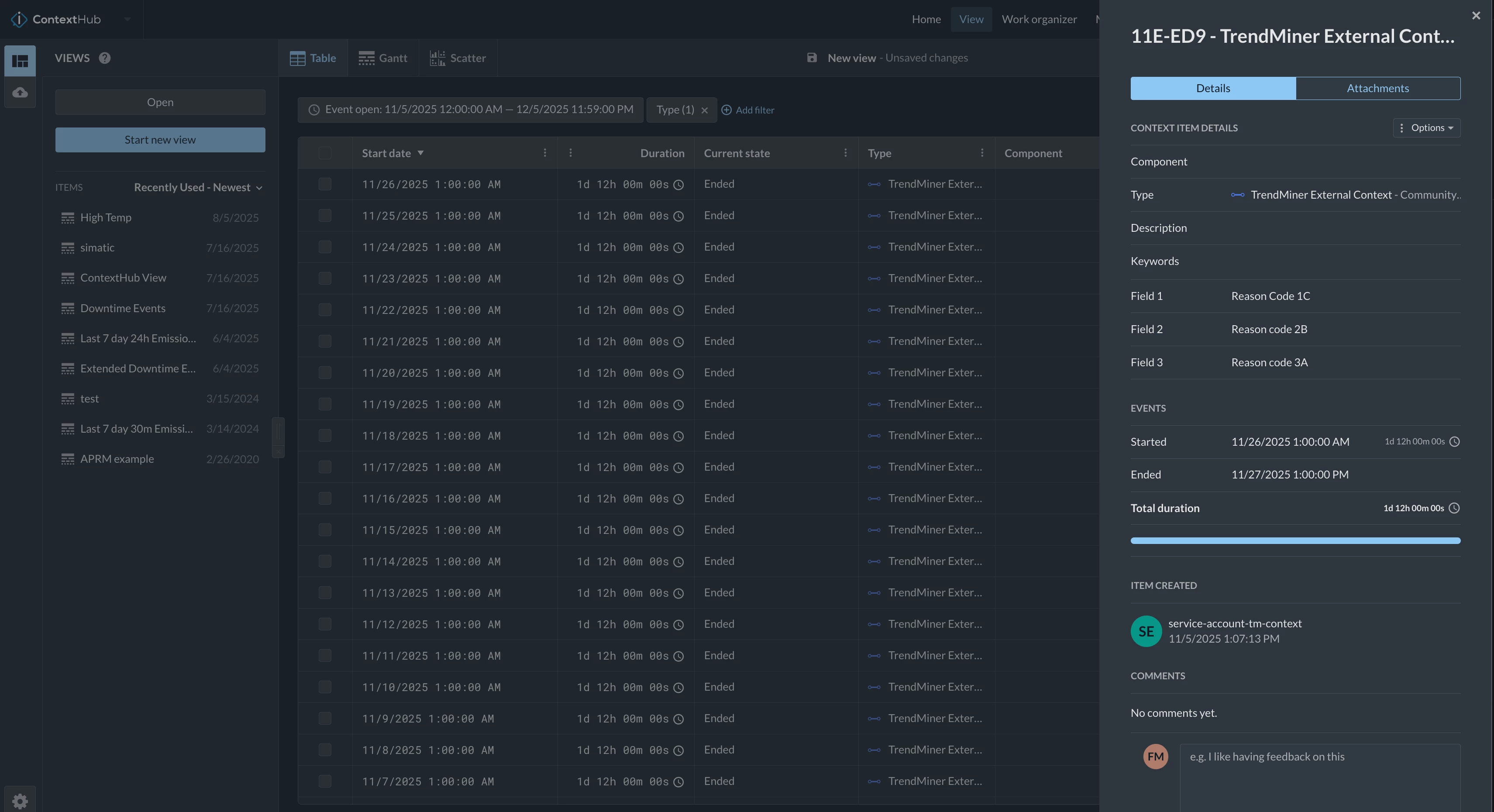
Testing Your Queries
Before deploying to production, it’s recommended to systematically test queries on your database (or a dummy copy of a partial Event set) to ensure proper syntax and selections.
1. Connection Testing
- Verify ODBC driver installation and configuration
- Test connection string with your ODBC data source tool
- Confirm authentication credentials work
2. Testing individual queries
Test each query independently using your database's query tool. A testing strategy is outlined below.
Events Query
- Replace
{AFTER}and{BEFORE}with actual timestamps - Set
{CURSOR}to NULL for the first page - Verify Started and Ended events are returned, and each have the
_0and_1suffixes - Check that pagination works with subsequent cursor values
Event by ID Query
- Test with actual event IDs including the
_0and_1suffixes - Verify it first correctly strips the suffix to select the record, and then returns the matching Start/End event
Types Query
- Test with
{CURSOR}as NULL - Verify all event types are returned with correct field associations
- Continue with a
{CURSOR}value to return subsequent pages
Type by ID Query
- Test with actual type IDs from your Types query results
- Verify the complete type definition is returned
Fields Query
- Test with
{CURSOR}as NULL - Verify all custom fields are defined properly
- Continue with a
{CURSOR}value to return subsequent pages
Field by ID Query:
- Test with actual field IDs from your Fields query results
- Verify field definition is complete
Event Fields Query:
- Test with actual event IDs (with
_0or_1suffix) - Verify only non-NULL field values are returned
- Check that field IDs match those in Types and Fields queries
Events by Grouping Key Query:
- Test with actual grouping keys (original IDs without suffix)
- Verify both start and end events for the same group are returned
3. Data Validation
- Ensure all timestamp fields are in the format specified by your
DateTimeFormatconfiguration - Ensure that column data types match what is required by TrendMiner, and apply necessary conversions (e.g. using TO_CHAR or other available functions)
4. Performance Testing
- Test queries with realistic date ranges
- Monitor query execution times
- If individual queries exceed 10-15 seconds, it is recommended to reduce the default page size
- Verify that proper indexes exist on frequently queried columns (e.g.
{ID})
Start small, scale up
Even though the first time setting up a context connection may look complex, in essence it’s only a translation and mapping of each of your table’s properties to the TrendMiner domain:
- The different types of events you have, each with its set of fields
- The fields that exist in your data set
- Each event identified by a unique ID, defined by a type
Reach out for assistance
In case you’d want TrendMiner to assist through a small service offering, e.g. to create your first context connection and fast-track your time to value, don’t hesitate to reach out to your TrendMiner contacts, like your CSM!