

In industrial data analysis, preprocessing sensor data is crucial for accurate results, especially when dealing with sudden, abnormal spikes. These spikes can distort your analysis and lead to incorrect conclusions if not addressed properly. In this article, I will show you how to eliminate spikes from your sensor data using four different methods in TrendMiner, ensuring that your analysis is reliable and accurate.
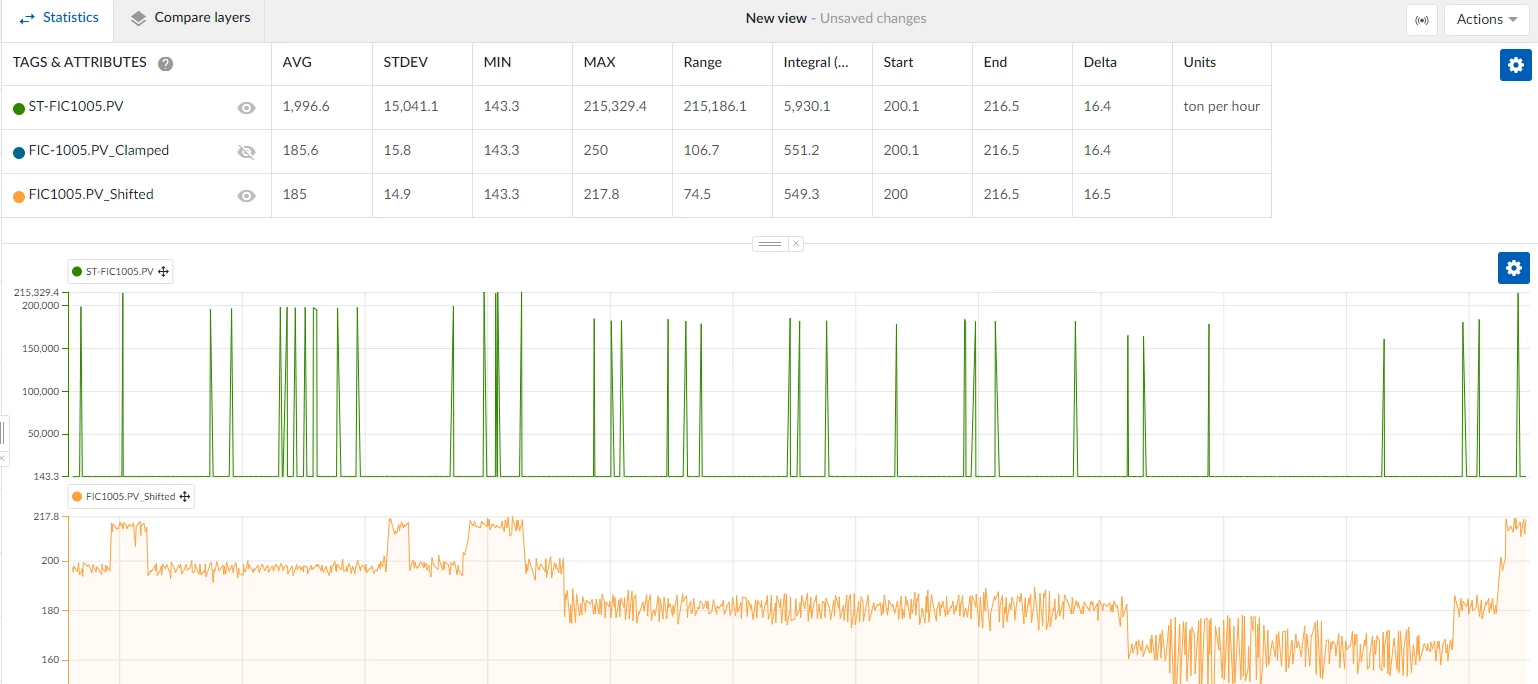
Examples of spikes in sensor data
Spikes in sensor data can occur due to various reasons such as sensor malfunctions, temporary communication errors, or unexpected events in the process. For instance, a sudden spike in temperature readings from a reactor might be caused by a faulty sensor rather than an actual temperature increase. Similarly, pressure spikes in a pipeline could be due to momentary errors in measurement. Removing these spikes from the dataset ensures that the analysis focuses on the real data and not on these anomalies.
Methods for getting rid of spikes
Option A: Create a filter based on a value-based search
- Perform a value-based search: Identify values smaller than the spikes in your dataset.
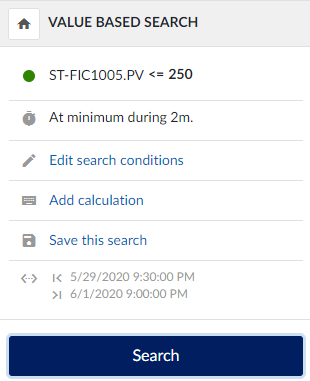
- Apply the filter: Use the "Keep results" function to exclude the spikes from your data.
- View the statistics: Once applied, the statistics table will show values without the influence of spikes.
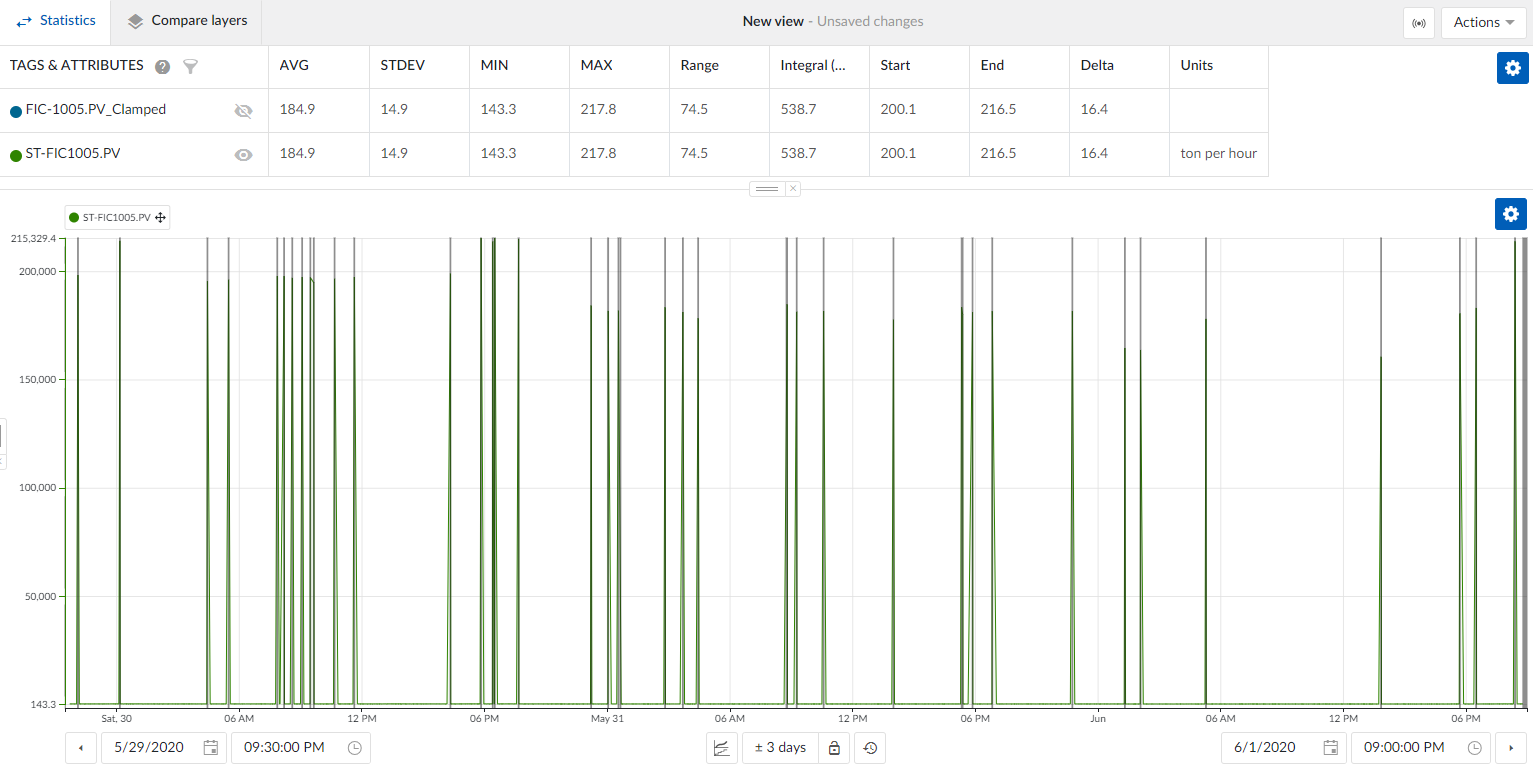
The advantage of this method is that it is quick and easy to implement, though it offers less flexibility for more complex analysis in the next steps.
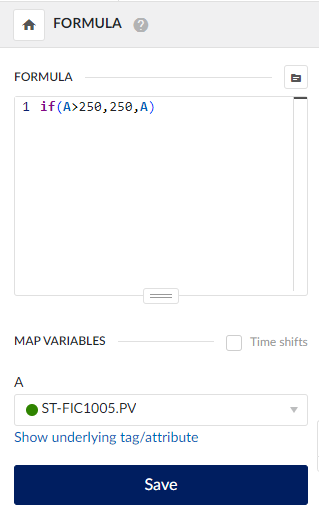
Option B: Clamping the data with a formula
- Create a formula: Apply a formula to cap the spikes at a maximum value. For example: if(A>250,250,A), where A is the original tag with spikes.
- View the statistics: The values in the statistics table will now be capped, with no spikes exceeding 250.
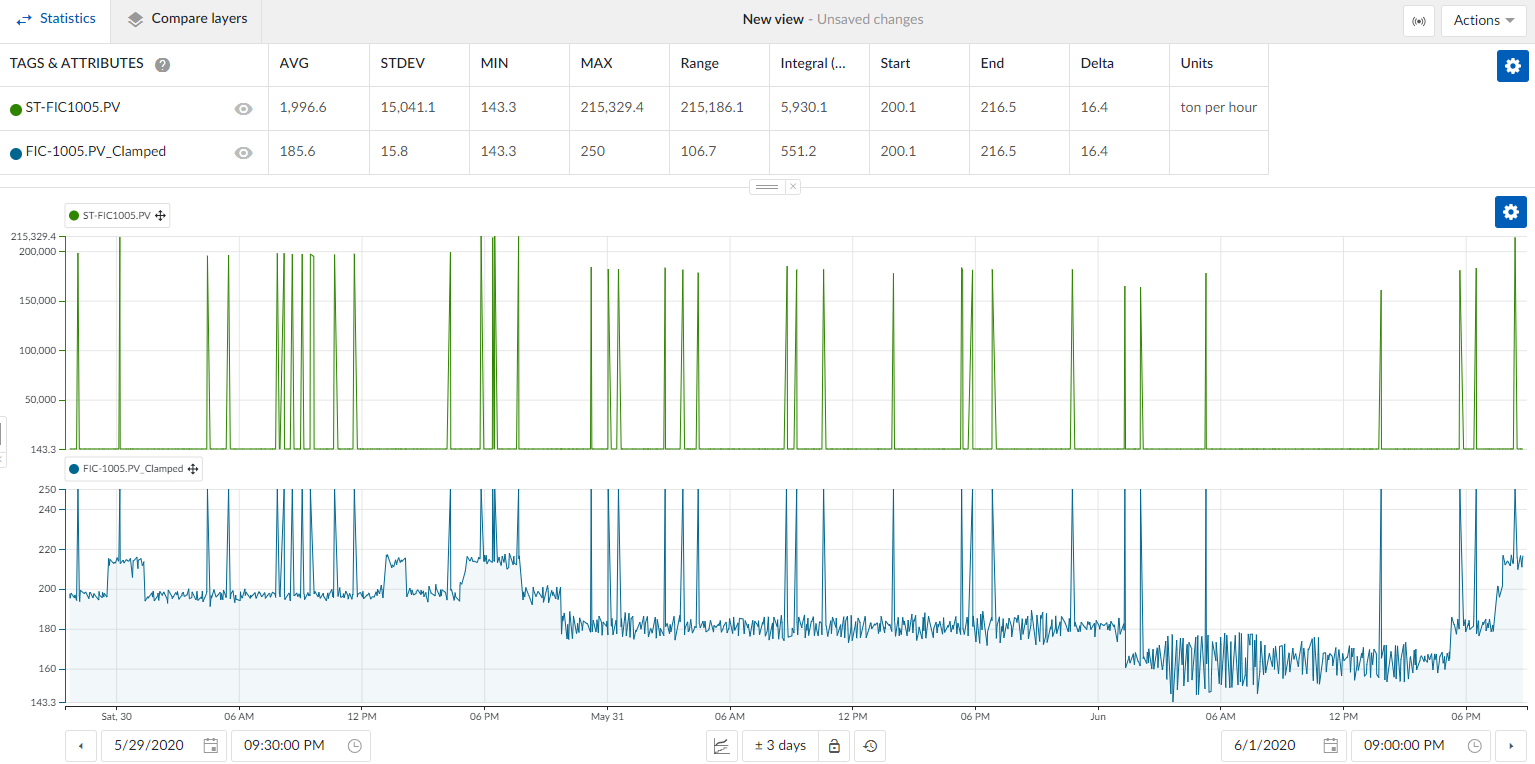
This method is simple to implement and offers flexibility, but there is a small loss of accuracy in the data due to clamping.
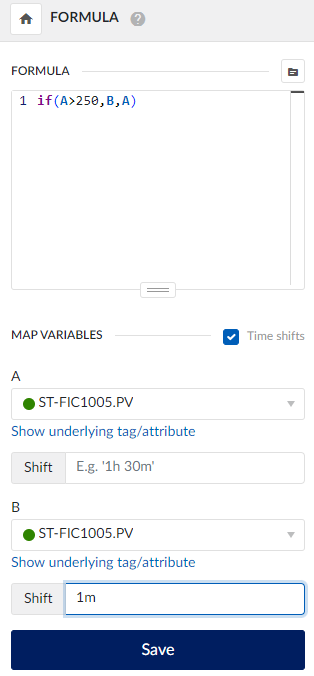
Option C: Create a time-shifted tag with a formula
- Create a formula: Use the last good value to replace the spikes. For example: if(A>250,B,A), where A is the original tag, and B is the original tag shifted by 1 minute.
- View the statistics: The spikes will be replaced by the last valid value, resulting in a cleaner dataset.
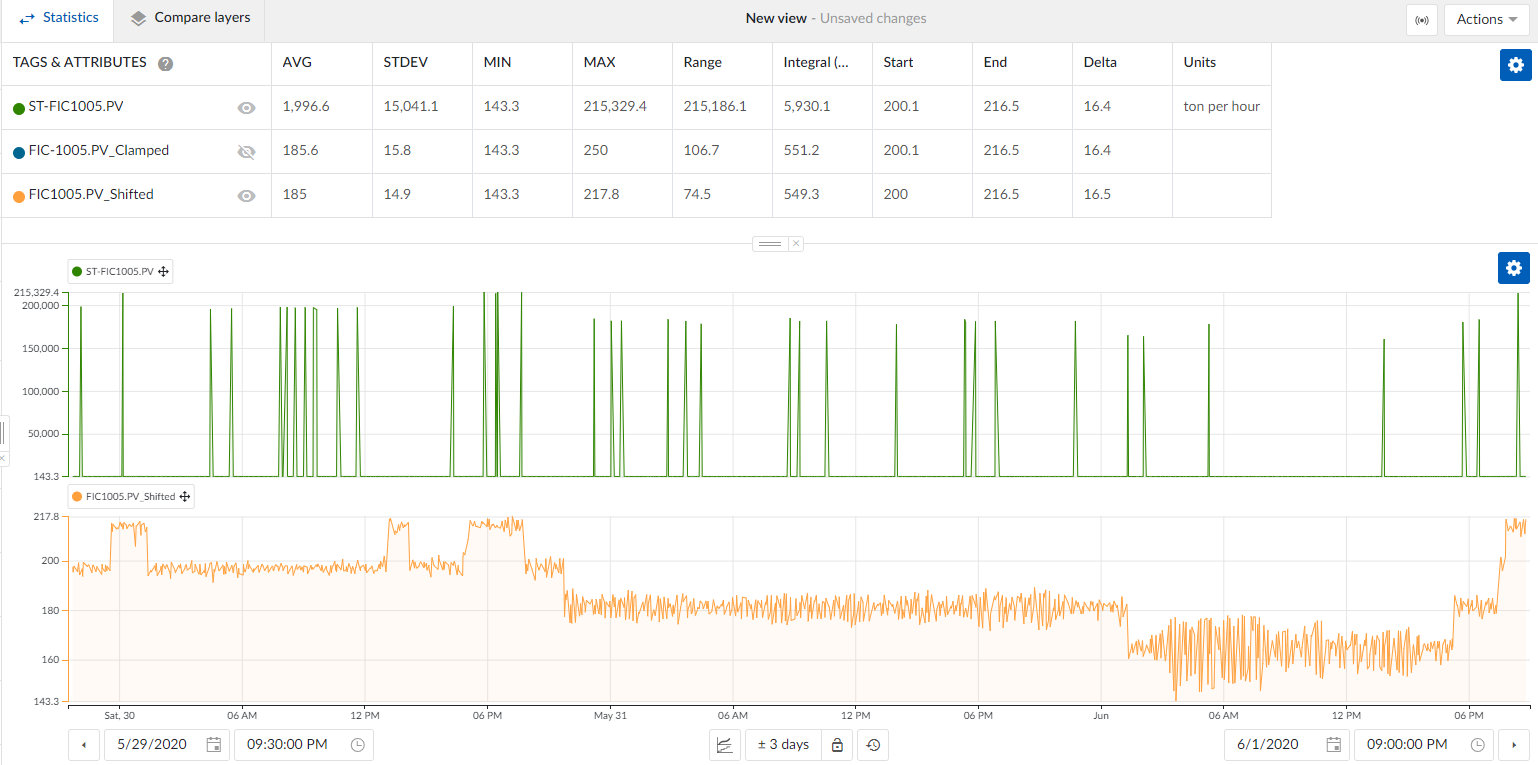
This method provides accurate results, but it may require some fine-tuning to suit more complex datasets.
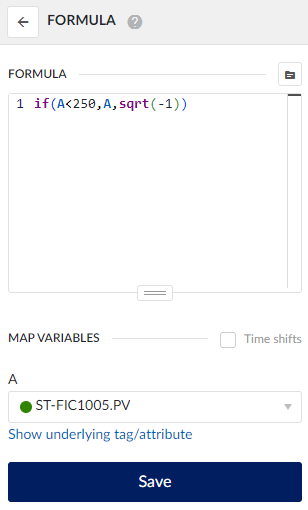
Option D: Create an interpolated tag with a formula
- Create a formula: Linearly interpolate between valid data points. For example: if(A<250,A,sqrt(-1)), where A is the original tag.
- View the statistics: Spikes are removed, and the data is smoothly interpolated, providing a more realistic representation.
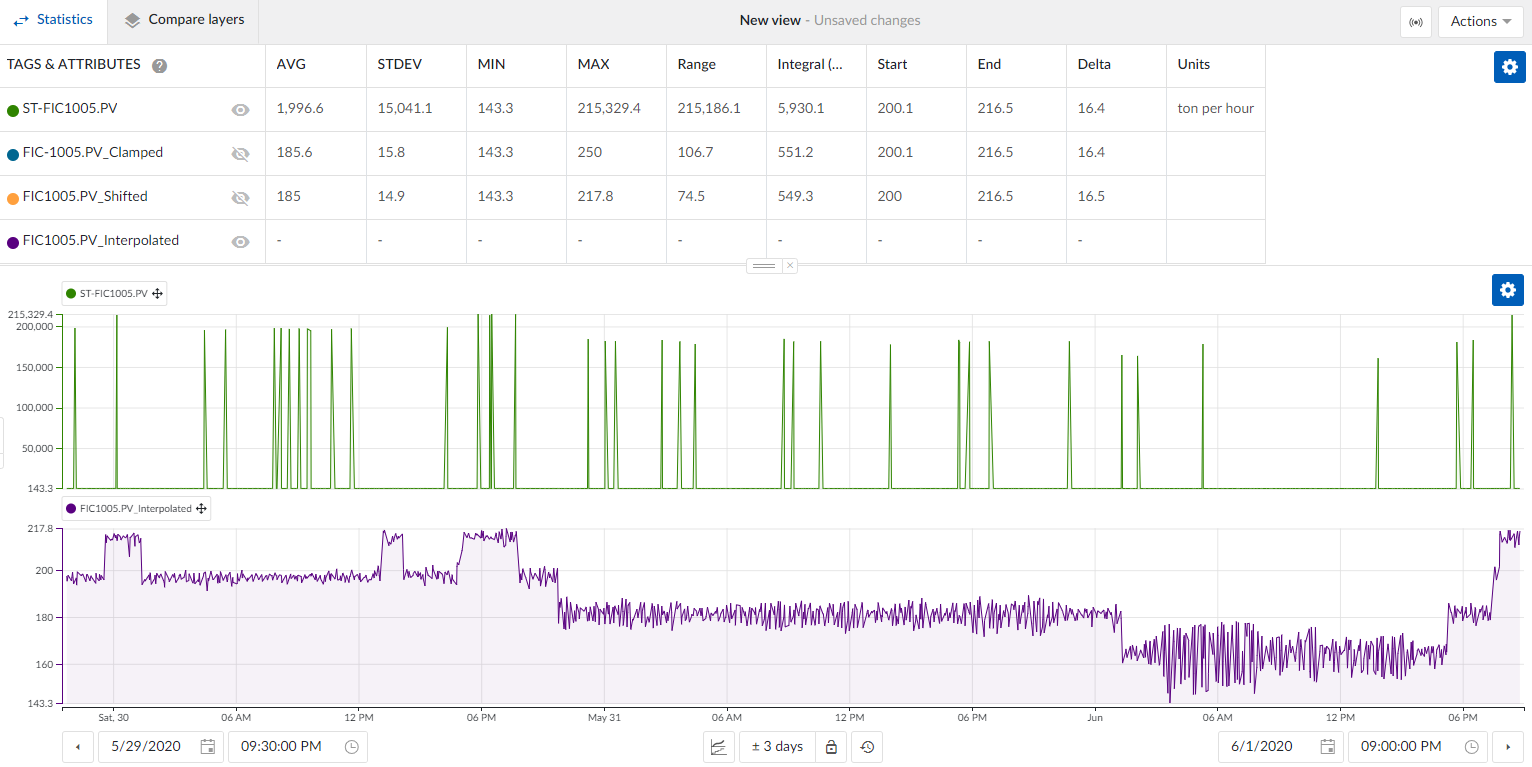
This option offers very accurate results, though it may need adjustments depending on the complexity of the data patterns.
Benefit
By removing spikes from sensor data, these methods allow for cleaner, more reliable datasets, leading to more accurate and actionable insights. Depending on your specific requirements, you can choose the method that best suits your needs, whether for quick filtering or precise interpolation. This ensures that your analyses reflect actual process conditions, minimizing the risk of false conclusions caused by faulty or erroneous data points.