Hello,
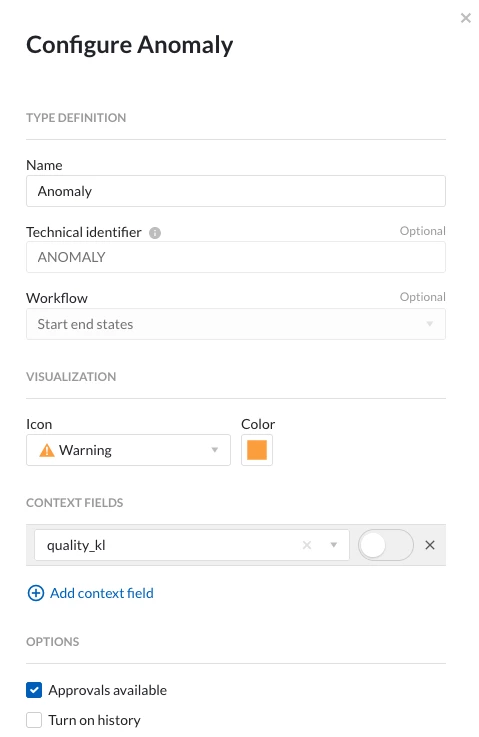
I am currently developing a dashboard to monitor the nitrogen consumption of our production lines. Each line consists of several machines connected to nitrogen tanks, and we have flow measurement devices for each machine. I have defined two types of anomalies for these machines:
- Nitrogen consumption when idle: to detect unintended leaks.
- Nitrogen overconsumption when running: to detect deviations from normal flow.
For this purpose, I have included two surveillance tiles for each machine in the line-specific dashboard. However, my goal is to create a high-level dashboard that provides an overview of all lines, showing if there is an issue with any particular line. From there, users could click a link to access the detailed dashboard for that line.
My question is: Is it possible to monitor from the general dashboard whether anomalies are occurring on the lower-level dashboards? The searches I use for the detailed dashboards are based on conditions like “over X value during Y minutes,” and these vary by machine. Therefore, I cannot simply replicate the same logic for multiple machines and combine them into one tile.
I considered using a context item search, but surveillance tiles do not seem to allow these types of searches to trigger an alarm, so that approach does not work. Do you know if what I am trying to achieve can be done with the current tools available?
Thank you for your help.